心血管疾病(CVD)是ICU糖尿病患者的主要死亡原因,早期预测CVD风险对ICU患者至关重要,有助于临床决策和靶向干预。
# 数据清洗
df = df.dropna()
df = df.drop(columns=['patient_id'])
scaler = StandardScaler()
x_df = data[num_cols + cat_cols + other_cvd_col]
feature_names = x_df.columns.tolist()
x_train_df, x_test_df, y_train, y_test = train_test_split(x_df, y, test_size=0.2, random_state=2025, stratify=y)
ohe = OneHotEncoder(drop='first', handle_unknown='ignore', sparse_output=False)
x_train_cat_encoded = ohe.fit_transform(x_train_df[cat_cols])
x_test_cat_encoded = ohe.transform(x_test_df[cat_cols])
cat_encoded_cols = ohe.get_feature_names_out(cat_cols).tolist()
X_train_cat_df = pd.DataFrame(
x_train_cat_encoded,
columns=cat_encoded_cols,
index=x_train_df.index
).astype(np.float32)
X_test_cat_df = pd.DataFrame(
x_test_cat_encoded,
columns=cat_encoded_cols,
index=x_test_df.index
).astype(np.float32)
# 标准化数值变量
scaler = StandardScaler()
X_train_scaled_num = scaler.fit_transform(x_train_df[num_cols])
X_test_scaled_num = scaler.transform(x_test_df[num_cols]) # 使用训练集的 scaler
X_train_num_df = pd.DataFrame(
X_train_scaled_num,
columns=num_cols,
index=x_train_df.index
).astype(np.float32)
X_test_num_df = pd.DataFrame(
X_test_scaled_num,
columns=num_cols,
index=x_test_df.index
).astype(np.float32)
# 合并数值和编码后的分类变量
X_train_scaled_df = pd.concat([X_train_num_df, X_train_cat_df], axis=1)
X_test_scaled_df = pd.concat([X_test_num_df, X_test_cat_df], axis=1)
# LASSO特征选择
X = df.drop(columns=['cvd'])
Y = df['cvd']
lasso = Lasso(alpha=0.1)
lasso.fit(X_scaled, Y)
selected_features = X.columns[lasso.coef_ != 0]
X_selected = X[selected_features]
# 训练XGBoost模型
xgb_params_best = {
"learning_rate": bestparams["eta"],
"booster": bestparams["booster"],
"colsample_bytree": bestparams["colsample_bytree"],
"colsample_bynode": bestparams["colsample_bynode"],
"gamma": bestparams["gamma"],
"reg_lambda": bestparams["lambda"],
"min_child_weight": bestparams["min_child_weight"],
"max_depth": int(bestparams["max_depth"]),
"subsample": bestparams["subsample"],
"objective": "binary:logistic",
"rate_drop": bestparams["rate_drop"],
"n_estimators": int(bestparams["num_boost_round"]),
"verbosity": 0,
"eval_metric": "auc",
"base_score": 0.5
}
model = XGBClassifier(**xgb_params_best, random_state=2025)
model.fit(X_train, y_train)
# 模型评估
fpr1, tpr1, _ = roc_curve(y_test, y_pred_proba_1)
fpr2, tpr2, _ = roc_curve(y_test, y_pred_proba_2)
auc1 = roc_auc_score(y_test, y_pred_proba_1)
auc2 = roc_auc_score(y_test, y_pred_proba_2)
print(f'ROC-AUC: {auc1:.3f}')
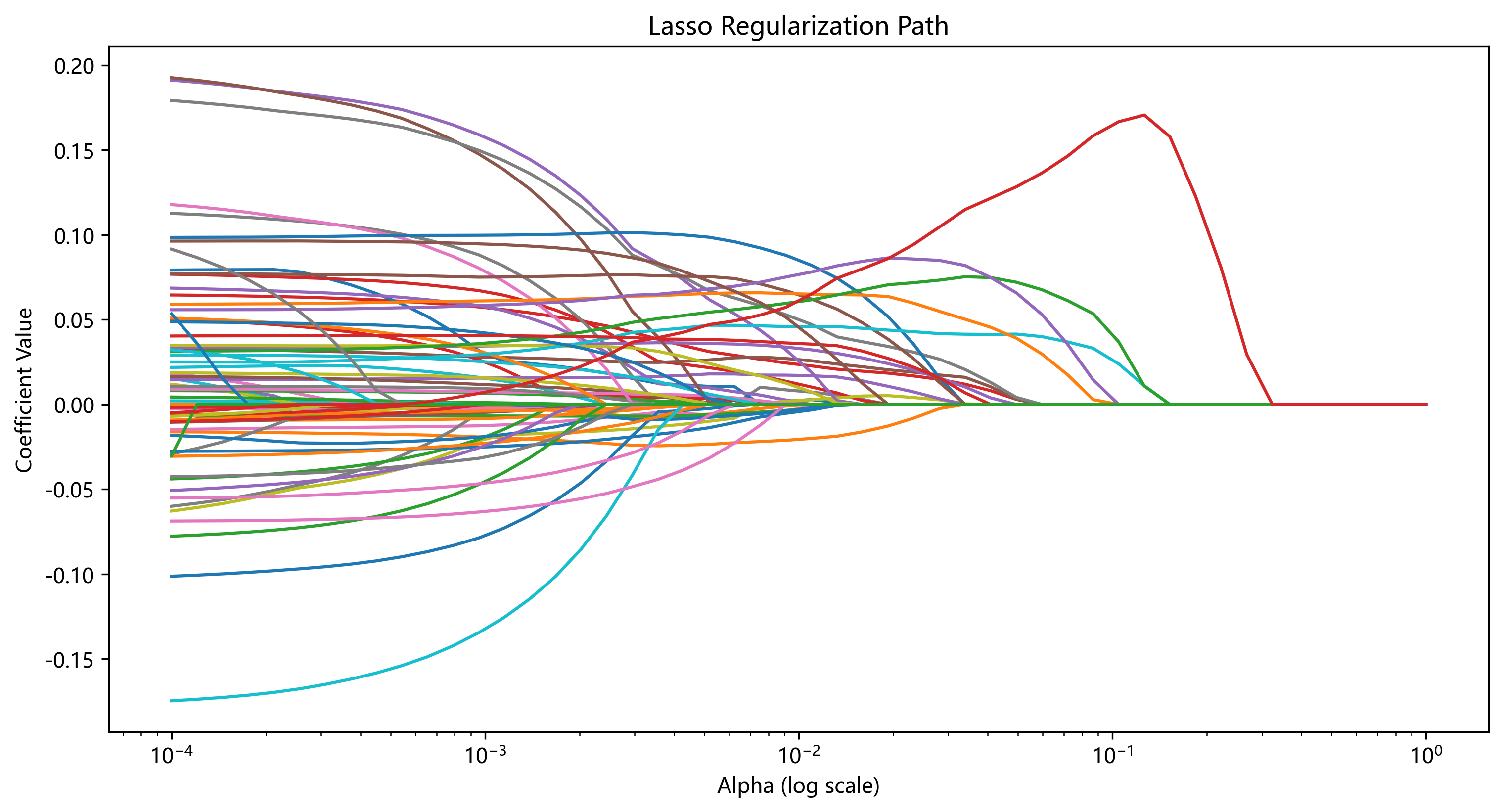
采用 LASSO(Least Absolute Shrinkage and Selection Operator)回归进行特征选择,通过对回归系数施记 𝐿1 正则化,实现变量压缩与冗余特征剔除。在交叉验证确定的最优惩罚参数𝜆下,原始纳入的 76 个候选特征中最终保留 57 个非零系数特征。这一过程有效降低了特征维度,缓解多重共线性问题,为后续 XGBoost 模型训练提供了更具判别力和稳定性的输入特征集合。
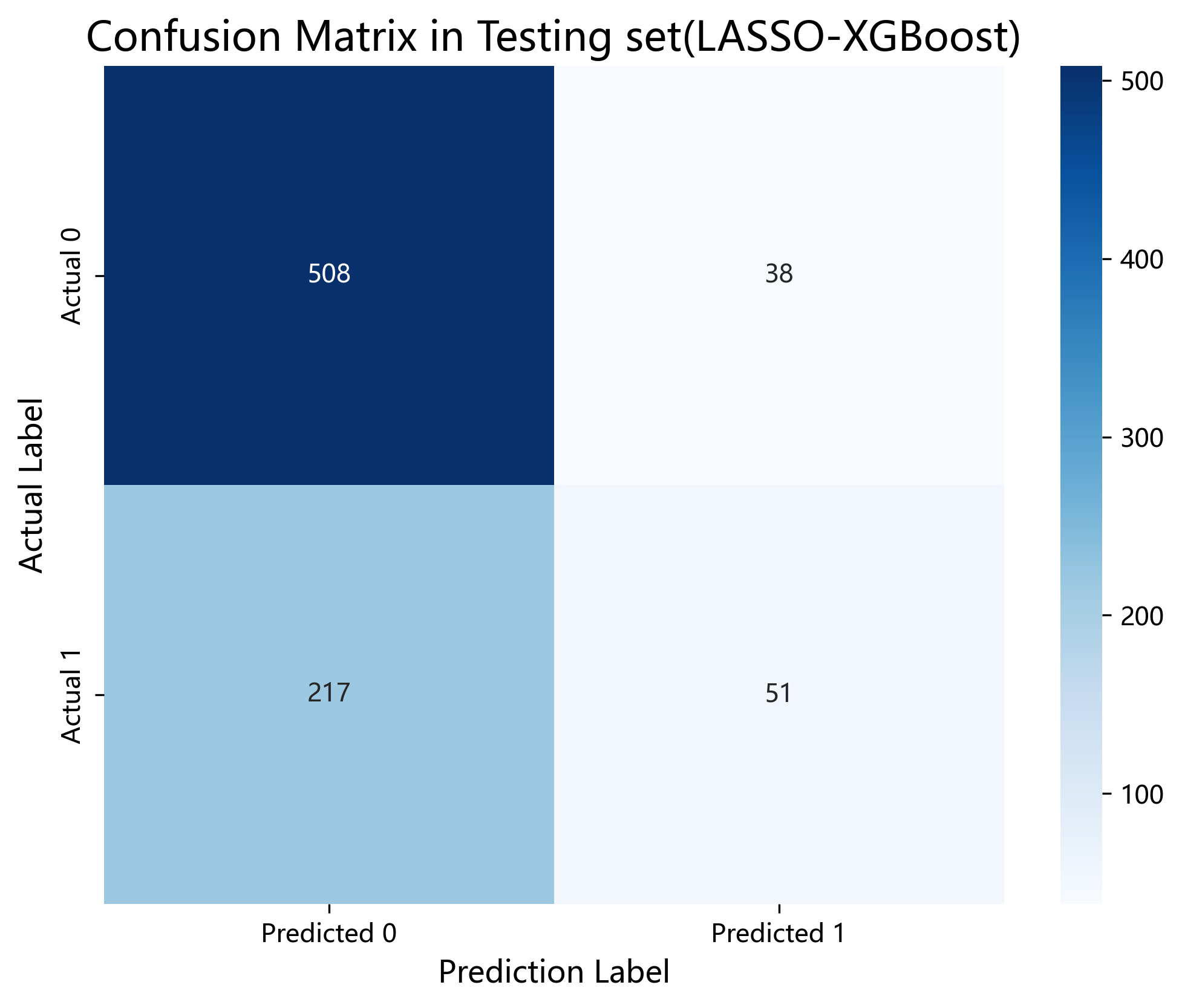
混淆矩阵系统性展示了模型在独立测试集上的分类结果,包括真阳性(TP)、真阴性(TN)、假阳性(FP)及假阴性(FN)的分布情况。结果显示,模型在维持较高真阴性识别能力的同时,能够较为有效地识别 CVD 高风险患者。该结果为模型在 ICU 场景下进行风险分层与辅助临床决策提供了直观依据,尤其有助于评估误判所可能带来的临床后果。
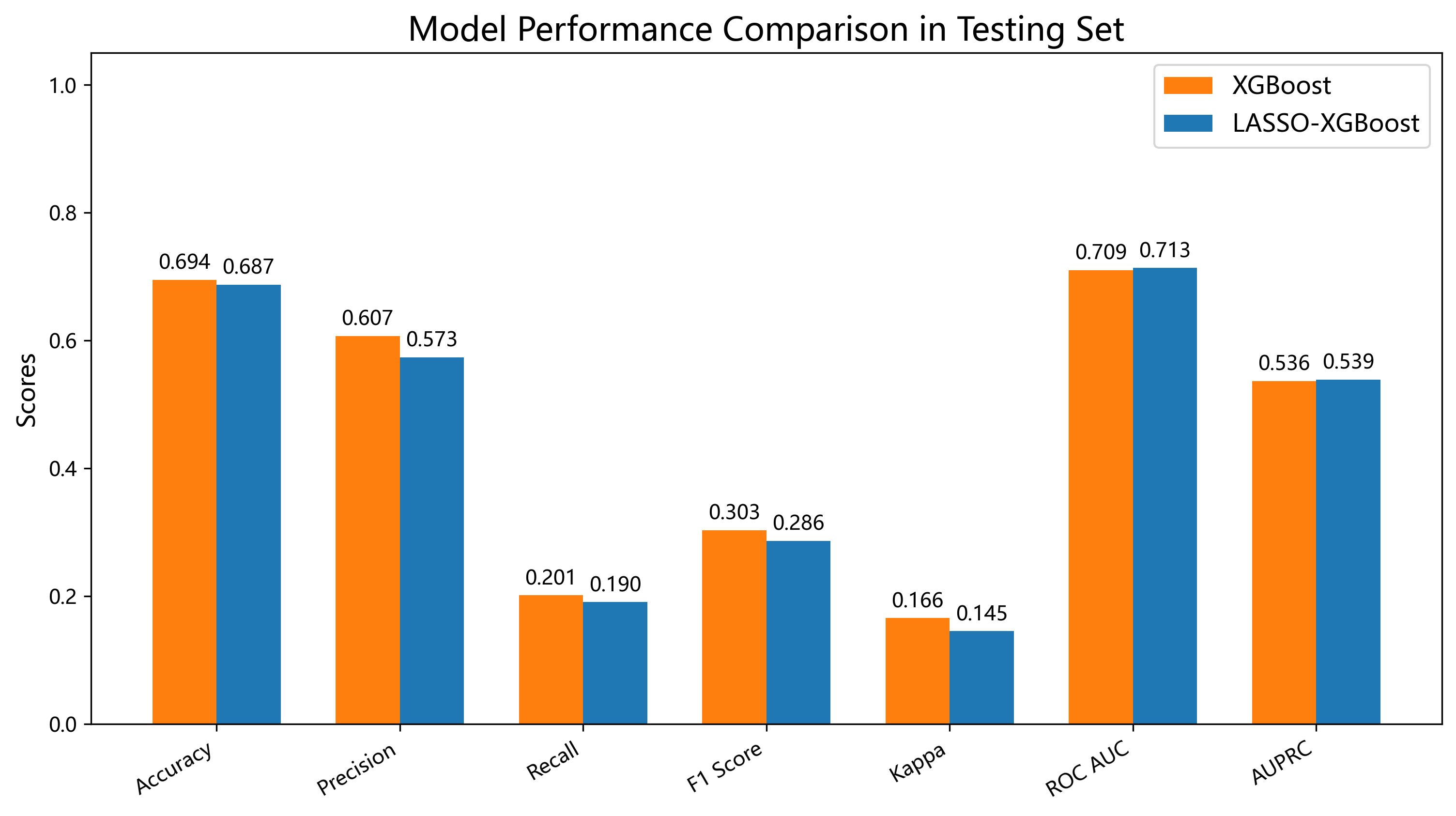
从多个互补指标对模型性能进行综合评估,包括 Accuracy、Precision、Recall、F1-score、Cohen’s Kappa、ROC AUC 及 AUPRC。
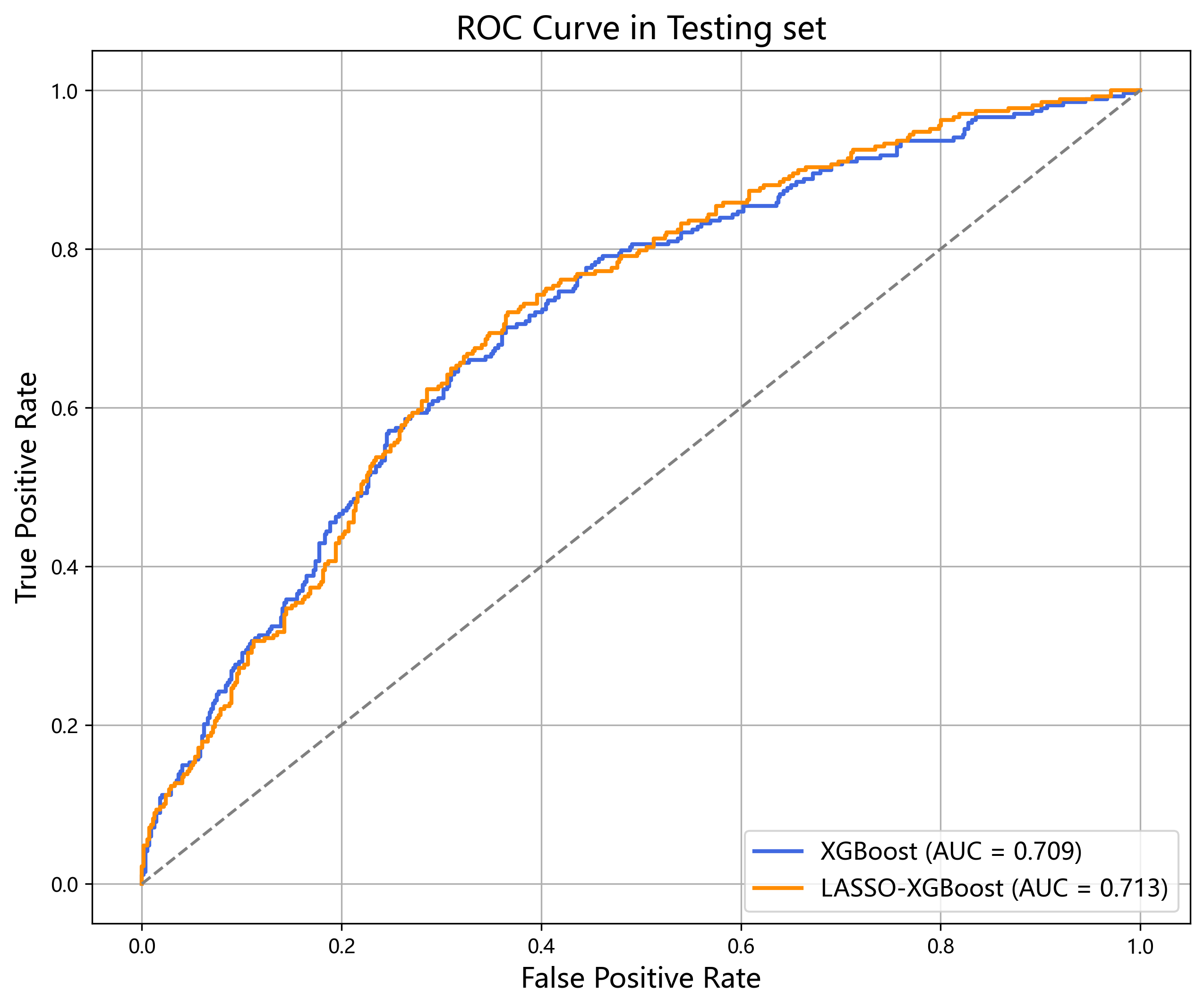
在总体 CVD 预测任务中,LASSO-XGBoost 模型的 AUROC 达到 0.713,表明模型具备较好的区分 CVD 与非 CVD 患者的能力。ROC 曲线在不同阈值下体现了灵敏度与特异度之间的权衡,为临床应用中阈值选择提供了依据。
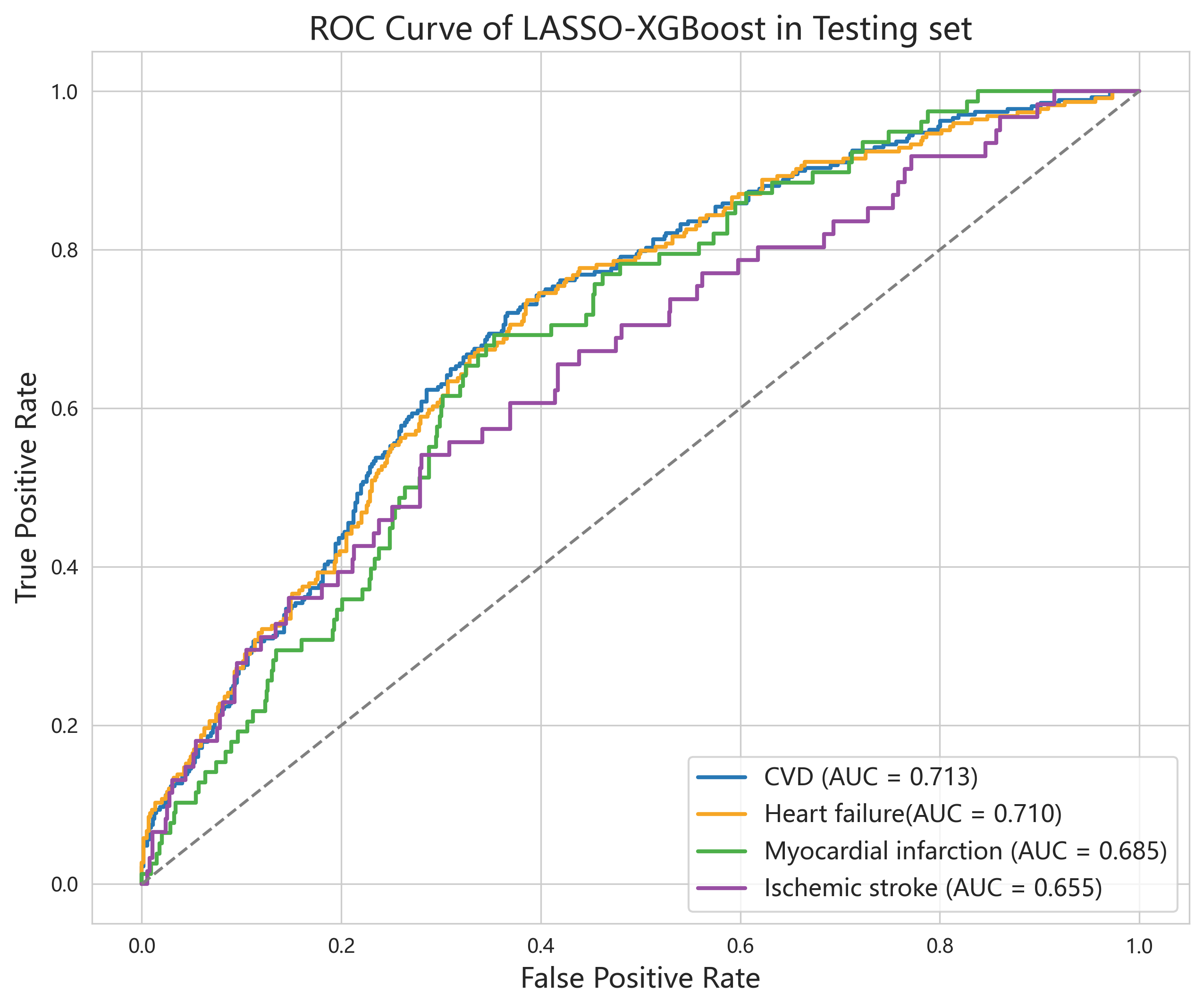
在 CVD 亚型分析中,模型对不同结局的预测性能存在一定差异:心力衰竭(HF)的 AUROC 为 0.710,心肌梗死(MI)为 0.685,缺血性卒中(IS)为 0.655。结果提示模型对心源性事件的识别能力相对更强,而对卒中结局的预测仍存在进一步优化空间。
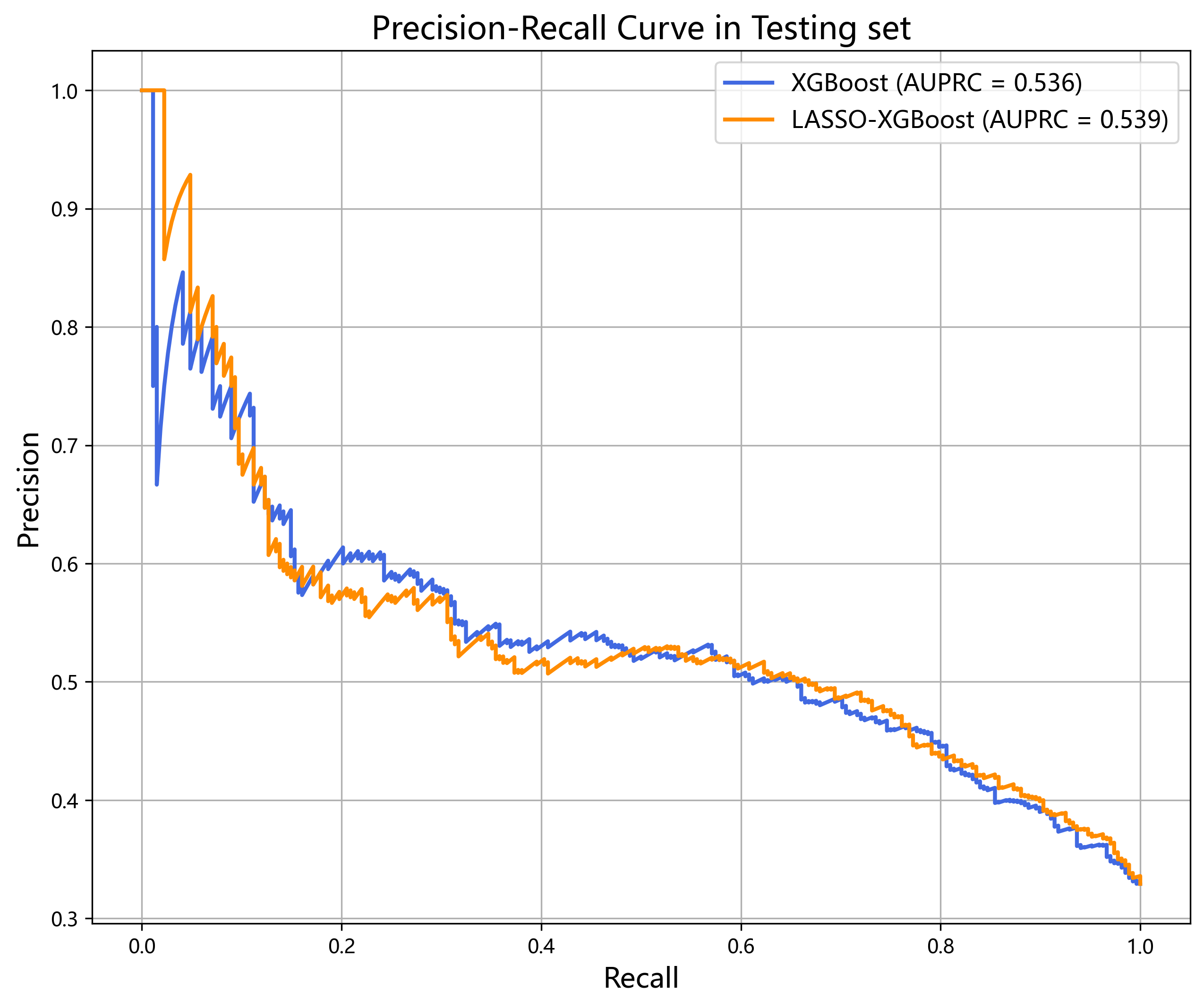
在类别不平衡的背景下,Precision-Recall 曲线更能反映模型对阳性事件的识别能力。LASSO-XGBoost 在 CVD 预测中的 AUPRC 为 0.539,提示模型在维持较高召回率的同时,仍具备合理的精确度水平,具有一定的临床实用潜力,尤其适用于高风险人群的早期筛查。
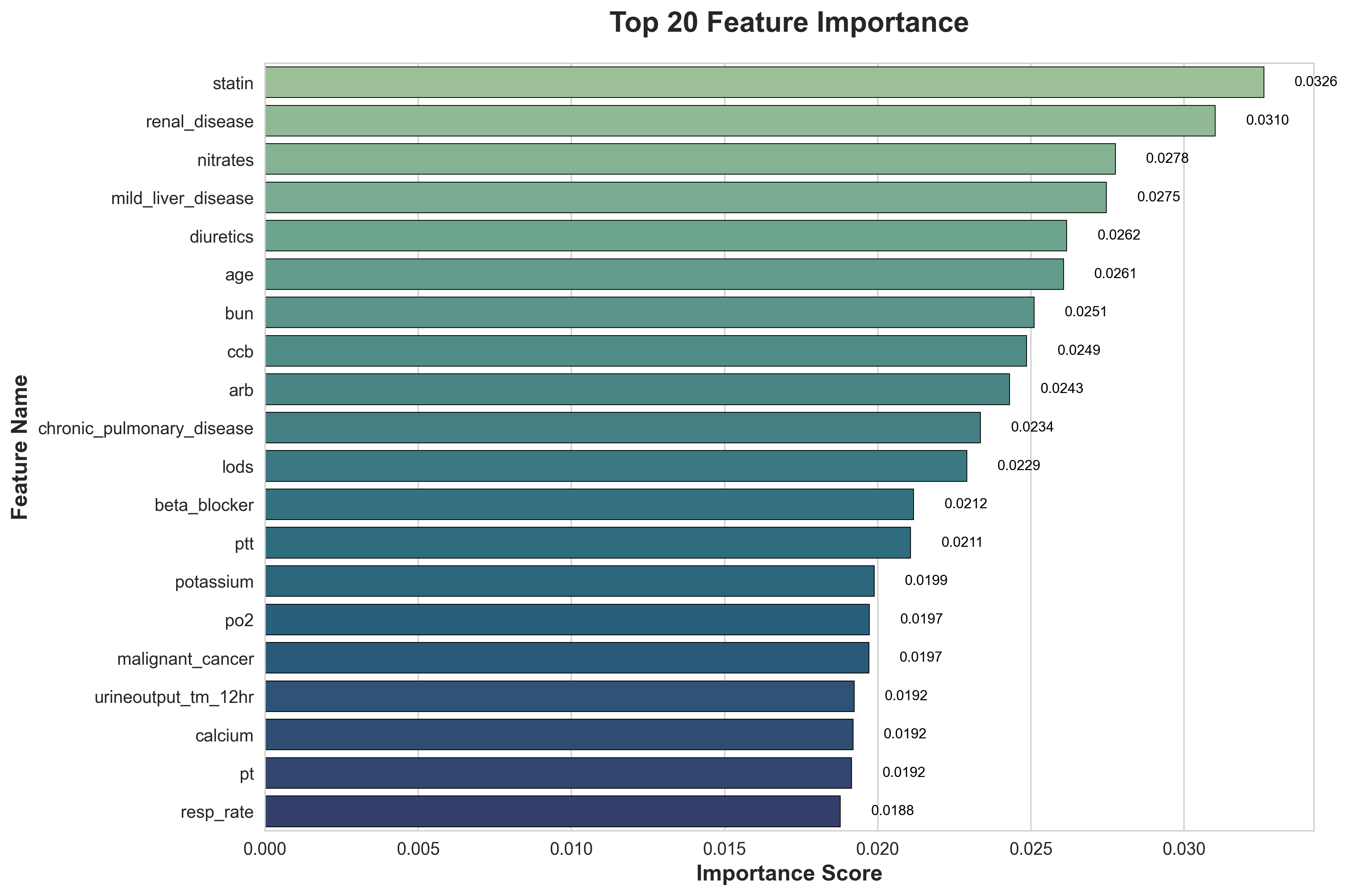
基于 XGBoost 的变量重要性(VIMP)分析显示,他汀类药物使用、肾病史、硝酸甘油应用以及轻度肝病在模型决策中占据核心地位。这些特征在模型分裂节点中的高频使用,反映了其在区分 CVD 风险方面的显著贡献,亦与既往临床认知高度一致。
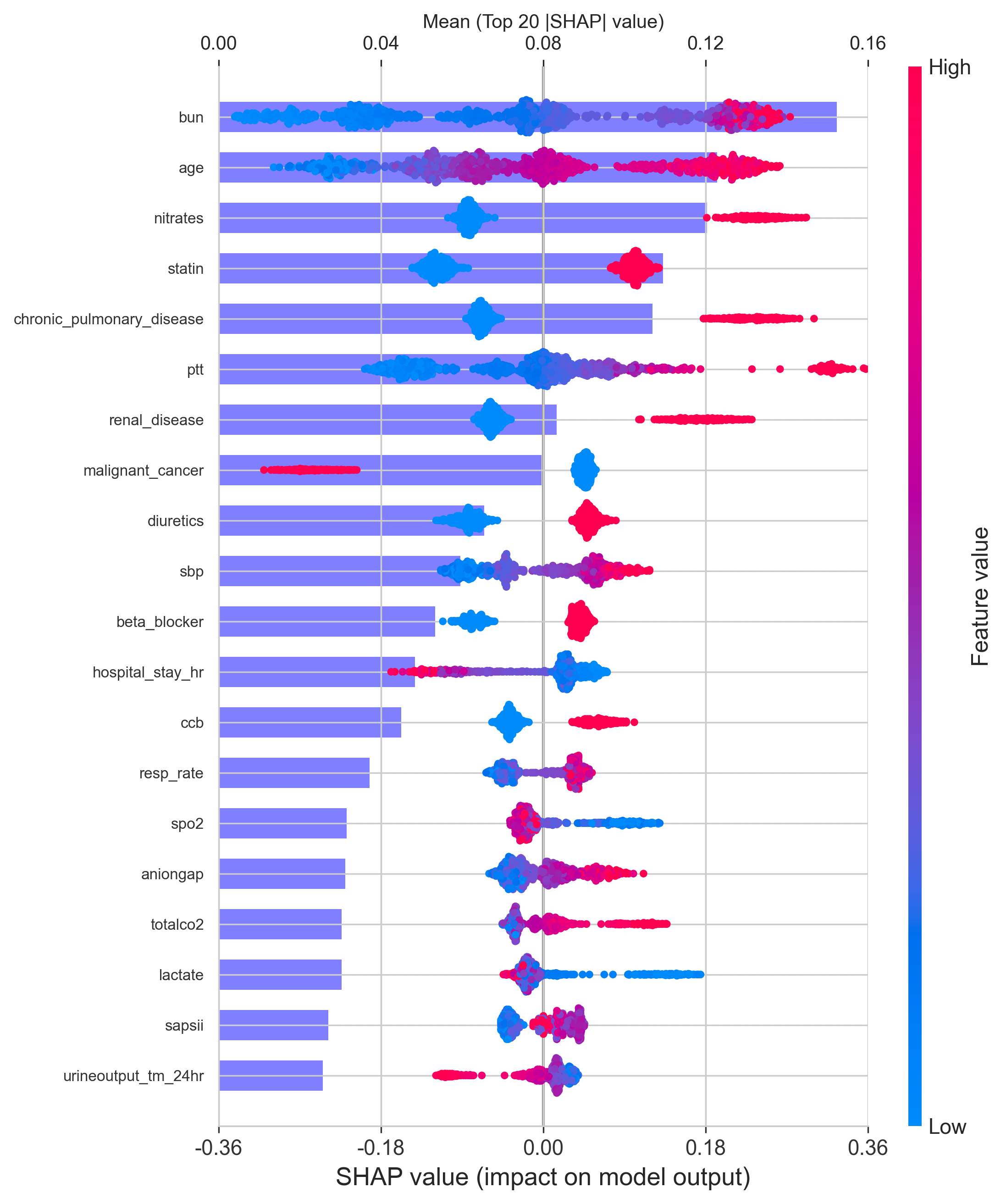
SHAP(SHapley Additive exPlanations)分析进一步揭示了特征对模型预测的方向性和个体层面影响。结果显示,BUN、年龄、硝酸甘油使用以及他汀类药物是驱动 CVD 风险预测的关键变量。其中,较高的 BUN 水平和年龄增长通常与更高的 CVD 预测风险相关。
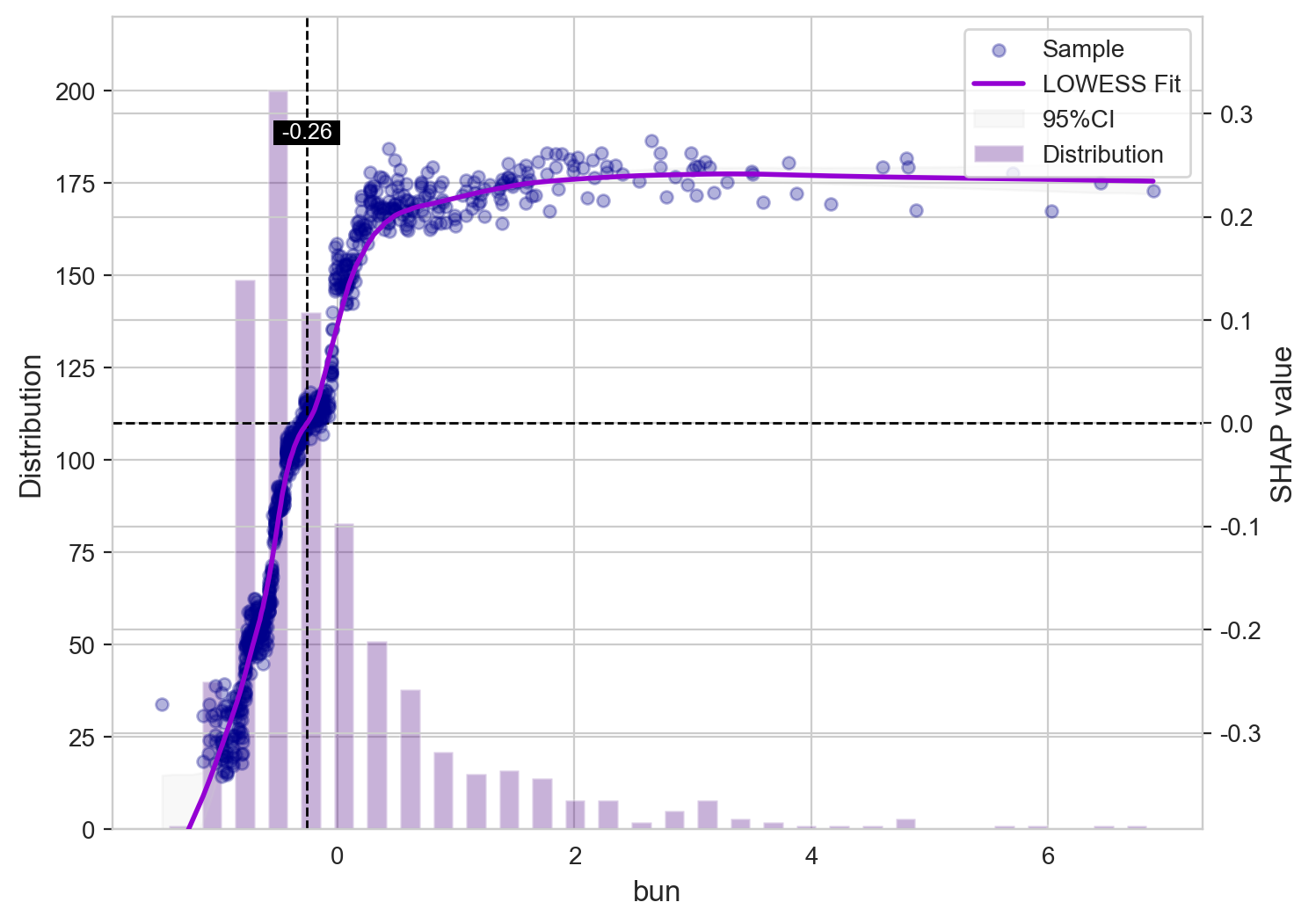
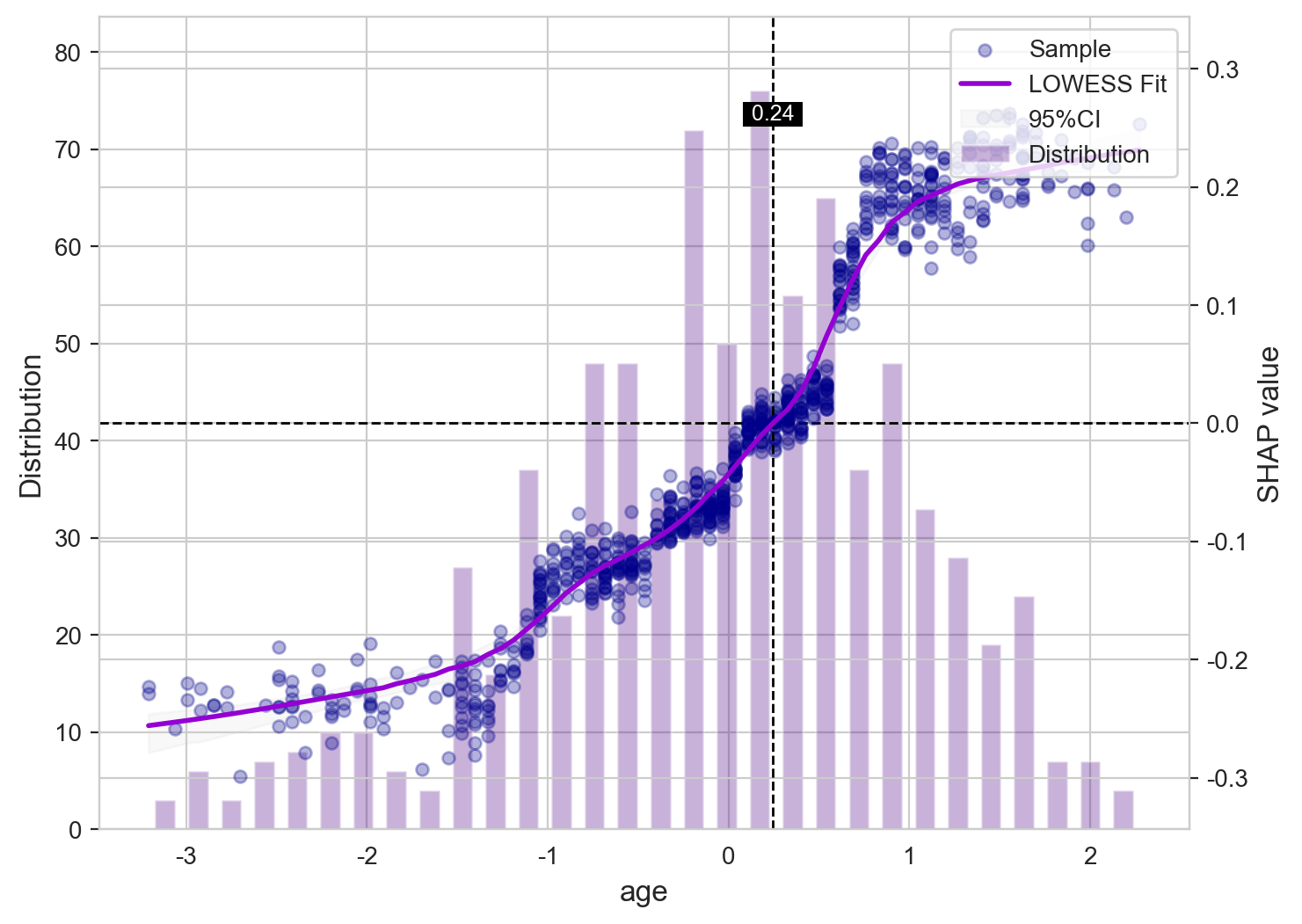
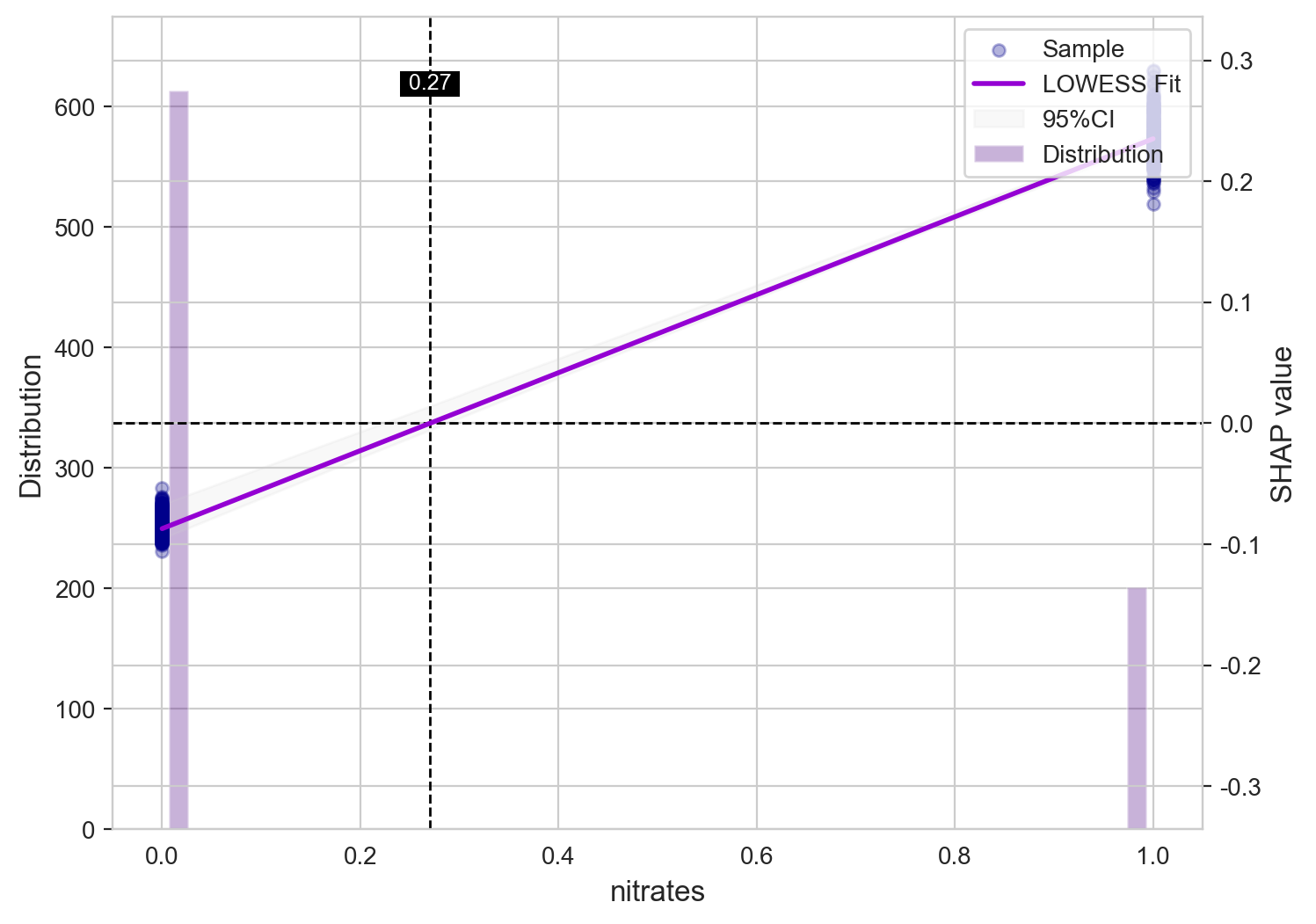
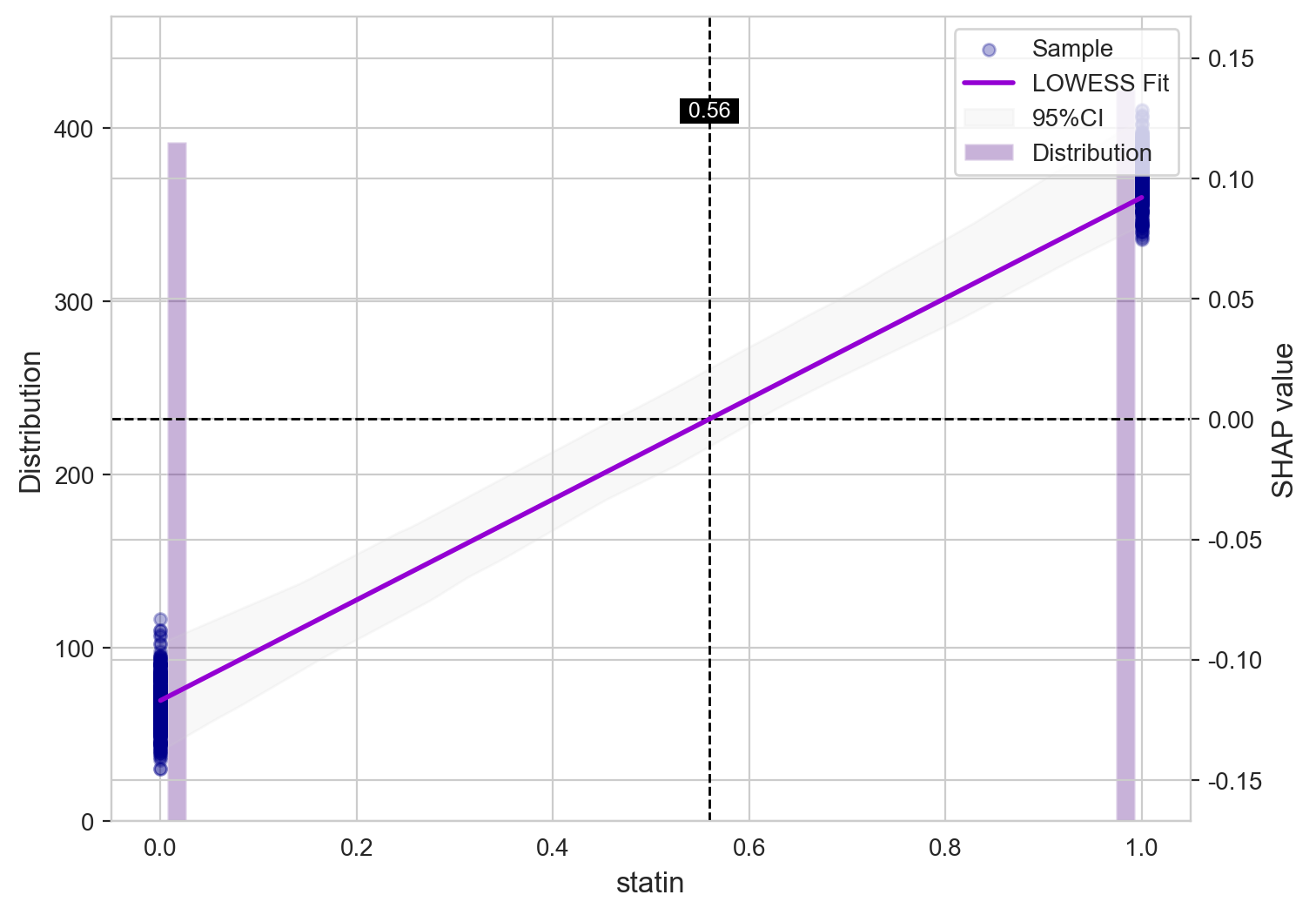
SHAP 依赖图展示了关键变量的剂量–效应关系:BUN 与年龄呈现出随数值升高而 CVD 风险逐渐增加的趋势;硝酸甘油和他汀类药物的影响则体现了治疗指征与潜在基础心血管风险之间的复杂交互关系。这些结果增强了模型的可解释性,为临床医生理解模型预测逻辑及其潜在应用场景提供了重要支持。